

Переезд, DeepSeek. В городе появился новый чемпион ИИ — и они американцы.
В четверг, AI2, некоммерческий исследовательский институт искусственного интеллекта, базирующийся в Сиэтле, выпустил модель, которую, по его утверждению, опередивает Deepseek V3, одну из ведущих систем китайской компании AI Deepseek.
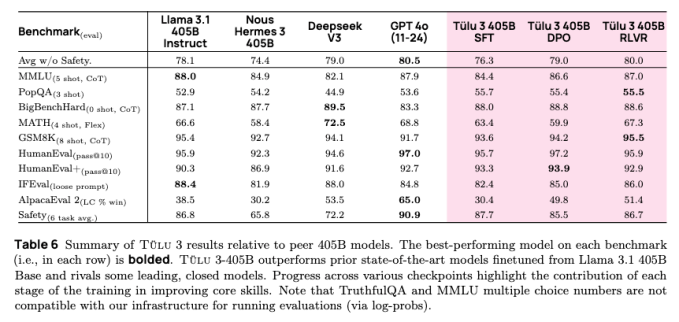
Модель AI2, называемая Tulu3-405B, также превосходит GPT-4O Openai по определенным тестам AI, согласно внутреннему тестированию AI2. Более того, в отличие от GPT-4O (и даже Deepseek V3), Tulu3-405b является открытым исходным кодом, что означает, что все компоненты, необходимые для воспроизведения с нуля, свободно доступны и допустимо лицензированы.
Представитель AI2 сказал TechCrunch, что лаборатория считает, что TULU3-405B «подчеркивает потенциал США, чтобы возглавить глобальное развитие лучших в своем классе генеративных моделей ИИ».
«Эта веха является ключевым моментом для будущего открытого ИИ, усиливающего позицию США в качестве лидера в конкурентных моделях с открытым исходным кодом»,-сказал представитель. «С этим запуском AI2 представляет мощную, разработанную США альтернативу моделям Deepseek-отмечает ключевой момент не только в разработке ИИ, но и в демонстрации, что США могут руководить конкурентоспособным ИИ с открытым исходным кодом независимо от технических гигантов. ”
TULU3-405B-довольно большая модель. Содержит 405 миллиардов параметров, он требовал 256 графических процессоров, работающих параллельно для обучения, согласно AI2. Параметры примерно соответствуют навыкам решения проблем, и модели с большим количеством параметров, как правило, работают лучше, чем с меньшим количеством параметров.
Согласно AI2, одним из ключей к достижению конкурентной работы с Tulu3-405B была метод, называемый подкреплением обучения с подтверждаемыми вознаграждениями. Подкрепление обучения с проверкой вознаграждений, или RLVR, обучает модели по задачам с «проверяемыми» результатами, такими как решение математических задач и следующие инструкции.
AI2 утверждает, что на эталоне Popqa набор из 14 000 специализированных вопросов знаний, полученных из Википедии, Tulu3-405B Beat не только Deepseek V3 и GPT-4O, но и модель Meta Llama 3.1 405b. Tulu3-405b также имел самые высокие показатели в своем классе в классе на GSM8K, тесте, содержащем проблемы математического уровня на уровне начальной школы.
Tulu3-405b доступен для тестирования через веб-приложение AI2 Chatbot, а код для обучения и точной настройки модели на GitHub. Получите его в то время, когда появится горячая-до того, как появится следующая флагманская модель искусственного интеллекта.

