


OpenAI никогда не раскрывала, какие именно данные она использовала для обучения Sora, своего искусственного интеллекта, генерирующего видео. Но, судя по всему, по крайней мере часть данных могла быть получена из стримов Twitch и прохождения игр.
Sora была запущена в понедельник, и я немного поигрался с ней (насколько позволяют проблемы с емкостью). Из текстового запроса или изображения Sora может создавать видеоролики продолжительностью до 20 секунд в различных соотношениях сторон и разрешениях.
Когда OpenAI впервые представила Sora в феврале, она намекнула на то, что обучала модель на видео Minecraft. Итак, я задался вопросом, какие еще прохождения видеоигр могут скрываться в обучающем наборе?
Кажется, довольно много.
Сора может создать видео, которое по сути является клоном Super Mario Bros. (если оно глючное):

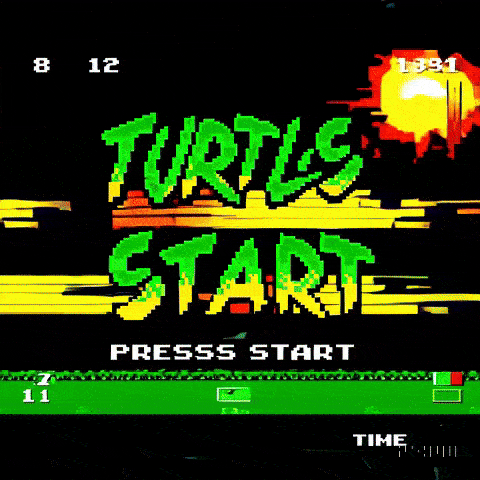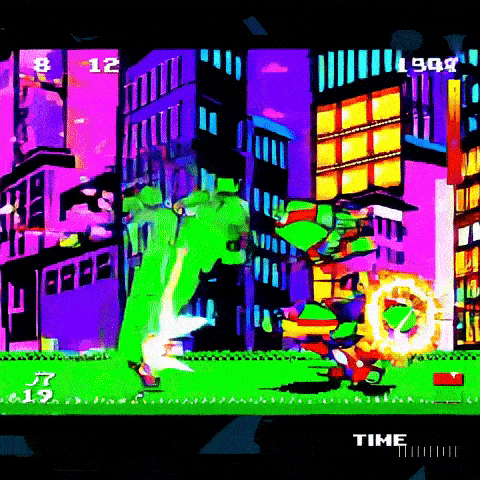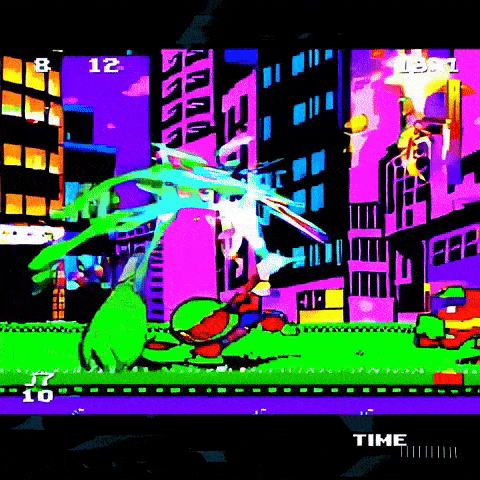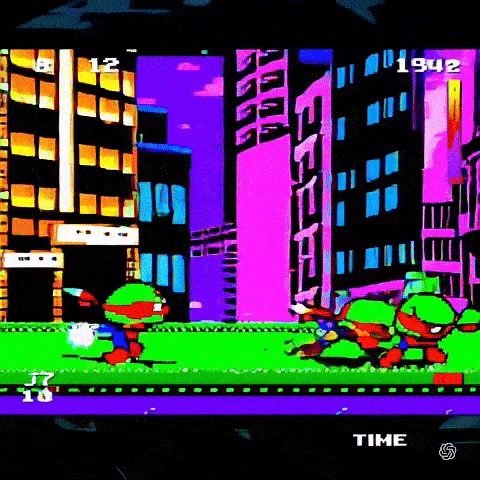
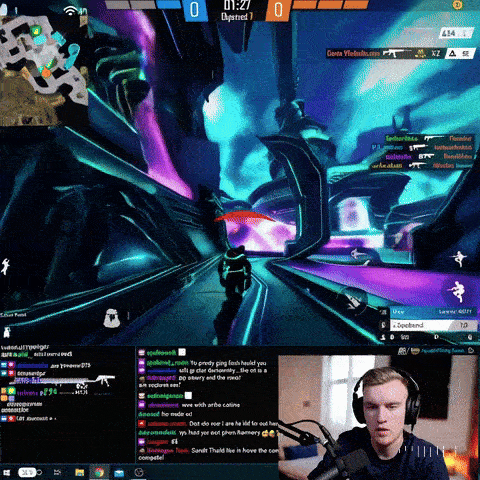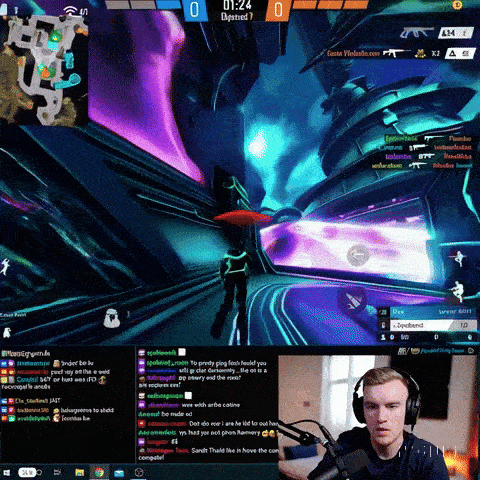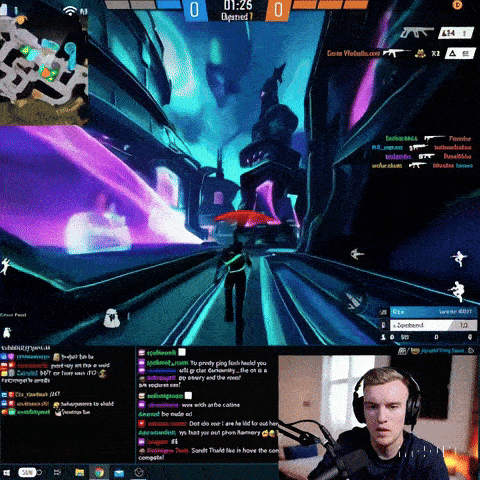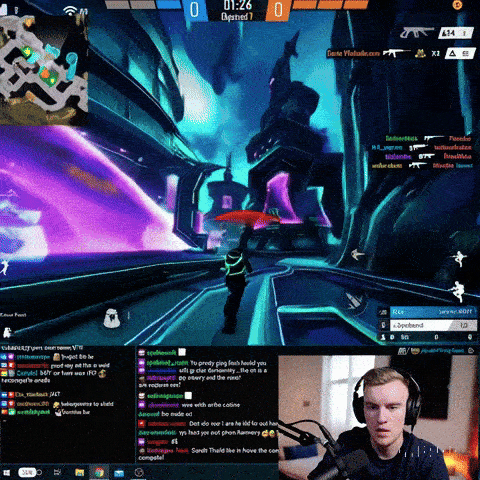
Он может создавать кадры игрового процесса шутера от первого лица, вдохновленные Call of Duty и Counter-Strike:
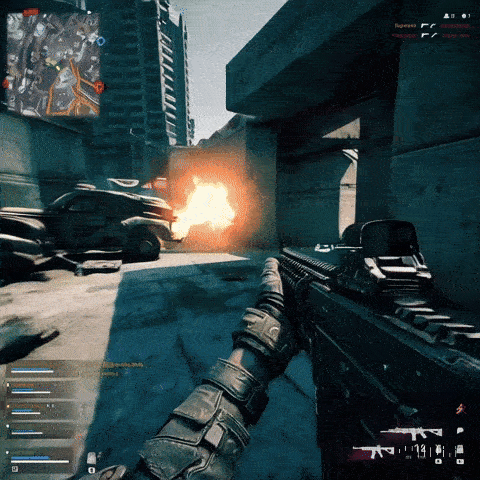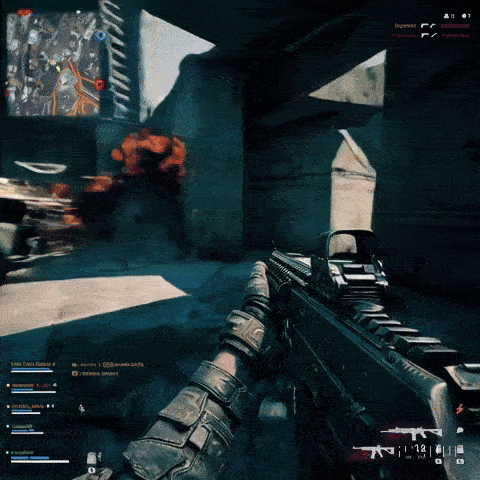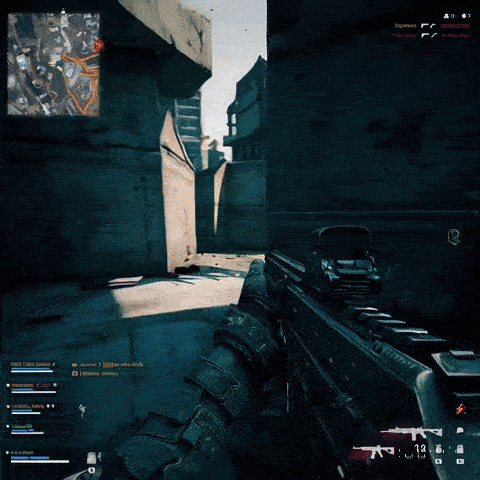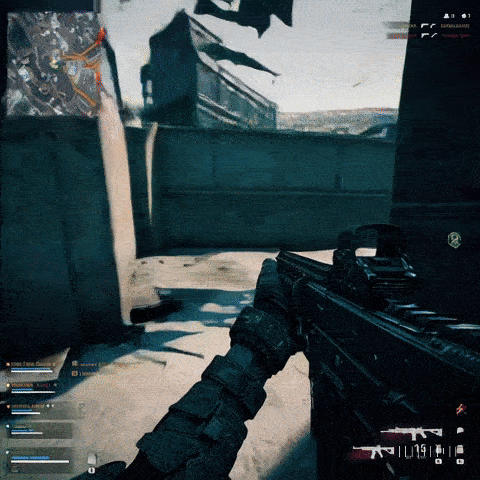
И он может выдать клип, показывающий аркадного бойца в стиле игры «Черепашки-ниндзя» 90-х годов:
Сора, похоже, также понимает, как должна выглядеть трансляция на Twitch — подразумевая, что он видел несколько таких. Посмотрите на скриншот ниже, на котором общие черты показаны правильно:
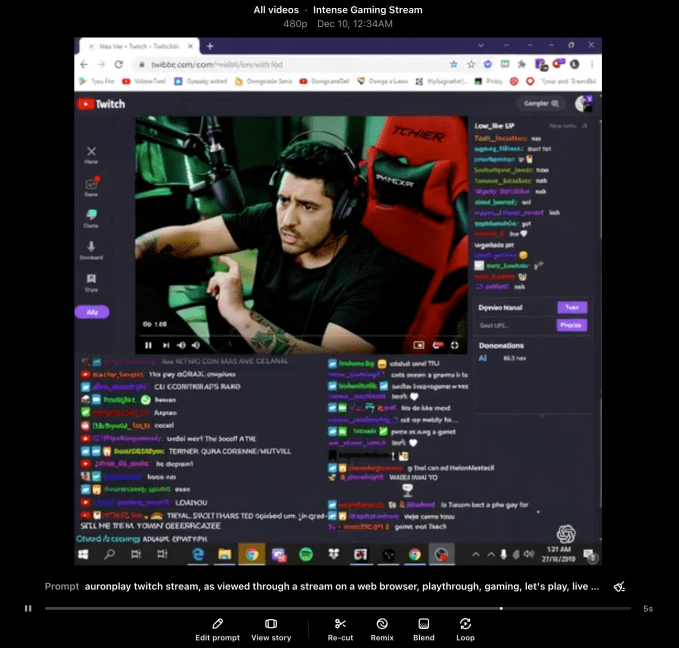
Еще одна примечательная особенность скриншота: на нем изображено изображение популярного стримера Twitch Рауля Альвареса Генеса, известного под псевдонимом Auronplay, вплоть до татуировки на левом предплечье Джинеса.
Auronplay — не единственный стример Twitch, которого, кажется, «знает» Сора. Он создал видео с персонажем, внешне похожим (с некоторыми художественными вольности) на Имане Анис, более известную как Покимане.
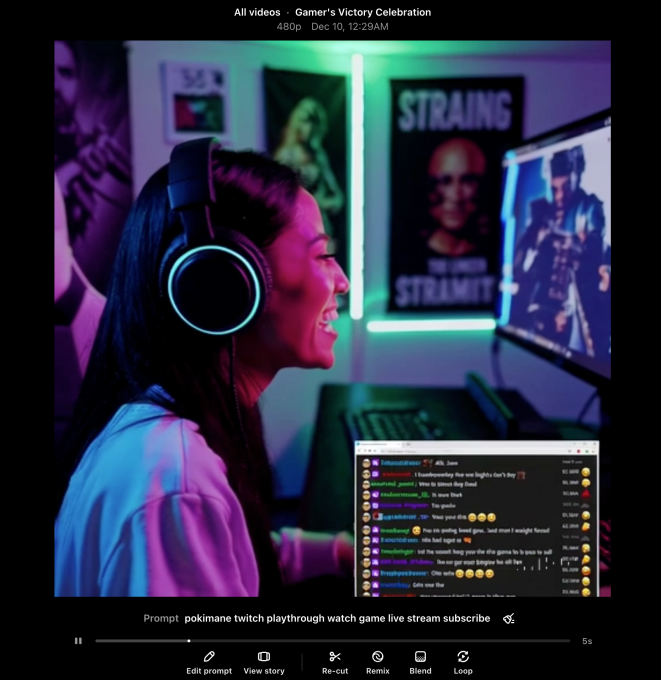
Конечно, мне пришлось проявить творческий подход к некоторым подсказкам (например, «игра с итальянским сантехником»). OpenAI реализовала фильтрацию, чтобы предотвратить создание Сорой клипов, изображающих персонажей, защищенных торговыми марками. Например, набрав что-то вроде «Геймплей Mortal Kombat 1», вы не получите ничего похожего на название.
Но мои тесты показывают, что игровой контент мог попасть в тренировочные данные Соры.
OpenAI уклончиво говорит о том, откуда он получает данные для обучения. В мартовском интервью The Wall Street Journal тогдашний технический директор OpenAI Мира Мурати не стала прямо отрицать, что Сора обучался работе с контентом на YouTube, Instagram и Facebook. А в технических спецификациях Sora OpenAI признала, что для разработки Sora она использовала «общедоступные» данные, а также лицензионные данные из стандартных медиа-библиотек, таких как Shutterstock.
OpenAI также не ответила на запрос о комментариях.
Если игровой контент действительно находится в обучающем наборе Sora, это может иметь юридические последствия, особенно если OpenAI создаст больше интерактивных возможностей на основе Sora.
«Компании, которые обучаются на нелицензионных материалах из видеоигр, подвергаются множеству рисков», — сказал TechCrunch Джошуа Вейгенсберг, адвокат по интеллектуальной собственности в Pryor Cashman. «Обучение генеративной модели ИИ обычно включает копирование обучающих данных. Если эти данные представляют собой видеопрохождения игр, весьма вероятно, что в обучающий набор будут включены материалы, защищенные авторским правом».
Вероятностные модели
Генеративные модели ИИ, такие как Сора, являются вероятностными. Обучившись на большом количестве данных, они изучают закономерности в этих данных, чтобы делать прогнозы — например, что человек, откусивший гамбургер, оставит след от укуса.
Это полезное свойство. Это позволяет моделям «узнавать», как устроен мир, в некоторой степени, наблюдая за ним. Но это также может быть ахиллесовой пятой. При определенном запросе модели, многие из которых обучаются на общедоступных веб-данных, создают почти копии своих обучающих примеров.
Понятно, что это вызвало недовольство авторов, чьи работы были использованы для обучения без их разрешения. Все большее число людей обращается за помощью в судебную систему.
На Microsoft и OpenAI в настоящее время подали в суд за то, что они якобы позволили своим инструментам искусственного интеллекта извергать лицензионный код. Три компании, стоящие за популярными приложениями для искусственного интеллекта, Midjourney, Runway и Stability AI, оказались под прицелом дела, обвиняющего их в нарушении прав художников. Крупнейшие музыкальные лейблы подали иск против двух стартапов, разрабатывающих генераторы песен на базе искусственного интеллекта, Udio и Suno, за нарушение авторских прав.
Многие компании, занимающиеся искусственным интеллектом, уже давно заявляют о защите добросовестного использования, утверждая, что их модели создают преобразующие, а не плагиатные работы. Суно, например, утверждает, что неразборчивое обучение ничем не отличается от «ребенка, пишущего свои собственные рок-песни после прослушивания этого жанра».
Но есть некоторые уникальные особенности игрового контента, говорит Эван Эверист, адвокат Dorsey & Whitney, специализирующийся на авторском праве.
«Видео прохождения включает как минимум два уровня защиты авторских прав: содержимое игры, принадлежащее разработчику игры, и уникальное видео, созданное игроком или видеооператором, отражающее опыт игрока», — сообщил Эверист TechCrunch по электронной почте. «А для некоторых игр существует потенциальный третий уровень прав в виде пользовательского контента, появляющегося в программном обеспечении».
Everist привел пример Fortnite от Epic, который позволяет игрокам создавать свои собственные игровые карты и делиться ими для использования другими. По его словам, видео прохождения одной из этих карт будет касаться не менее трех правообладателей: (1) Epic, (2) человека, использующего карту, и (3) создателя карты.
«Если суды примут решение об ответственности за авторские права за обучение моделей ИИ, каждый из этих правообладателей станет потенциальными истцами или источниками лицензирования», — сказал Эверист. «Для любого разработчика, обучающего ИИ на таких видео, подверженность риску экспоненциальна».
Вейгенсберг отметил, что в самих играх есть много «защищаемых» элементов, таких как фирменные текстуры, которые судья может принять во внимание при рассмотрении иска об интеллектуальной собственности. «Если эти работы не получили надлежащей лицензии, — сказал он, — обучение по ним может нарушать права».
TechCrunch обратился к ряду игровых студий и издателей за комментариями, включая Epic, Microsoft (владеет Minecraft), Ubisoft, Nintendo, Roblox и CD Projekt Red, разработчика Cyberpunk. Лишь немногие ответили, и никто не сделал официального заявления.
«В данный момент мы не сможем принять участие в интервью», — сказал представитель CD Projekt Red. EA сообщила TechCrunch, что «на данный момент не имеет никаких комментариев».
Рискованные выходы
Вполне возможно, что компании, занимающиеся искусственным интеллектом, смогут победить в этих юридических спорах. Суды могут решить, что генеративный ИИ преследует «весьма убедительную преобразующую цель», следуя прецеденту, созданному примерно десять лет назад в иске издательской индустрии против Google.
В этом случае суд постановил, что копирование Google миллионов книг для Google Books, своего рода цифрового архива, разрешено. Авторы и издатели пытались утверждать, что воспроизведение их интеллектуальной собственности в Интернете является нарушением авторских прав.
Но решение в пользу компаний, занимающихся искусственным интеллектом, не обязательно защитит пользователей от обвинений в правонарушениях. Если генеративная модель воспроизводит произведение, защищенное авторским правом, человек, который затем опубликовал это произведение — или включил его в другой проект — все равно может быть привлечен к ответственности за нарушение прав интеллектуальной собственности.
«Генераторные системы искусственного интеллекта часто выдают на выходе узнаваемые, охраняемые активы интеллектуальной собственности», — сказал Вайгенсберг. «У более простых систем, генерирующих текст или статические изображения, часто возникают проблемы с предотвращением создания материалов, защищенных авторским правом, в их выходных данных, и поэтому более сложные системы вполне могут столкнуться с той же проблемой, независимо от намерений программистов».

У некоторых компаний, занимающихся искусственным интеллектом, есть положения о возмещении ущерба, покрывающие такие ситуации, если они возникнут. Однако в этих положениях часто имеются исключения. Например, OpenAI применим только к корпоративным клиентам, а не к отдельным пользователям.
По словам Вайгенсберга, помимо авторских прав следует учитывать и риски, например, нарушение прав на товарные знаки.
«Результаты также могут включать в себя активы, которые используются в связи с маркетингом и брендингом, включая узнаваемых персонажей из игр, что создает риск товарного знака», — сказал он. «Или результаты могут создать риски для прав на имя, изображение и изображение».
Растущий интерес к моделям мира может еще больше усложнить все это. Одним из применений моделей мира, которым OpenAI считает Sora, является, по сути, создание видеоигр в реальном времени. Если эти «синтетические» игры будут напоминать контент, на котором обучалась модель, это может оказаться проблематичным с юридической точки зрения.
«Обучение платформы искусственного интеллекта голосам, движениям, персонажам, песням, диалогам и изображениям в видеоигре представляет собой нарушение авторских прав, так же, как если бы эти элементы использовались в других контекстах», — Эйвери Уильямс, юрист по судебным делам в области интеллектуальной собственности в McKool. Смит, сказал. «Вопросы, связанные с добросовестным использованием, которые возникли во многих судебных процессах против компаний, занимающихся генеративным искусственным интеллектом, повлияют на индустрию видеоигр так же, как и на любой другой творческий рынок».

