

Google DeepMind, ведущая исследовательская лаборатория Google в области искусственного интеллекта, хочет победить OpenAI в игре по созданию видео — и это может произойти, по крайней мере, на некоторое время.
В понедельник DeepMind анонсировала Veo 2, ИИ следующего поколения, генерирующий видео, и преемника Veo, который обеспечивает растущее число продуктов в портфолио Google. Veo 2 может создавать клипы продолжительностью более двух минут в разрешении до 4k (4096 x 2160 пикселей).
Примечательно, что это в 4 раза больше разрешения и более чем в 6 раз больше продолжительности, чего может достичь Sora OpenAI.
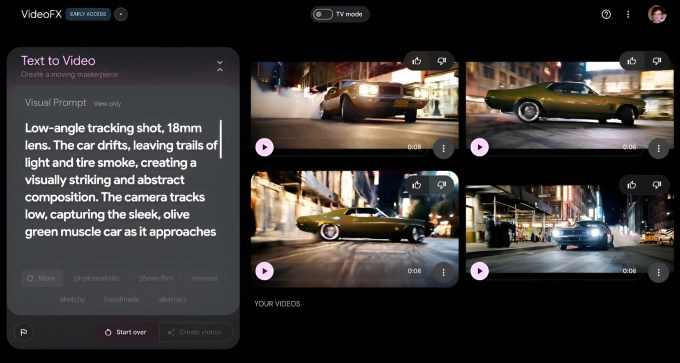
На данный момент это теоретическое преимущество, конечно. В экспериментальном инструменте создания видео Google VideoFX, эксклюзивно для которого теперь доступен Veo 2, видео ограничено разрешением 720p и продолжительностью восемь секунд. (Sora может создавать 20-секундные клипы с разрешением до 1080p.)
VideoFX находится в списке ожидания, но Google заявляет, что расширяет число пользователей, которые смогут получить к нему доступ на этой неделе.
Эли Коллинз, вице-президент по продуктам DeepMind, также сообщил TechCrunch, что Google сделает Veo 2 доступным через свою платформу для разработчиков Vertex AI, «поскольку модель будет готова к масштабному использованию».
«В ближайшие месяцы мы продолжим работу на основе отзывов пользователей, — сказал Коллинз, — и (мы) постараемся интегрировать обновленные возможности Veo 2 в интересные варианты использования в экосистеме Google… (Мы ожидаем) чтобы поделиться новыми обновлениями в следующем году».
Более управляемый
Как и Veo, Veo 2 может создавать видео по текстовой подсказке (например, «Машина мчится по автостраде») или по тексту и эталонному изображению.
Так что же нового в Veo 2? Что ж, DeepMind утверждает, что модель, которая может генерировать клипы в различных стилях, имеет улучшенное «понимание» физики и элементов управления камерой и производит «более четкие» кадры.
Говоря «Четче», DeepMind означает, что текстуры и изображения в клипах становятся более четкими, особенно в сценах с большим количеством движения. Что касается улучшенных элементов управления камерой, они позволяют Veo 2 более точно позиционировать виртуальную «камеру» в видеороликах, которые она генерирует, и перемещать эту камеру, чтобы снимать объекты и людей под разными углами.
DeepMind также утверждает, что Veo 2 может более реалистично моделировать движение, динамику жидкости (например, налитый в кружку кофе) и свойства света (например, тени и отражения). По словам DeepMind, это включает в себя различные линзы и кинематографические эффекты, а также «тонкие» человеческие выражения.

На прошлой неделе DeepMind поделился с TechCrunch несколькими отобранными образцами из Veo 2. Видео, созданные искусственным интеллектом, выглядели довольно хорошо — даже исключительно хорошо. Veo 2, кажется, хорошо разбирается в преломлении и сложных жидкостях, таких как кленовый сироп, и умеет имитировать анимацию в стиле Pixar.
Но, несмотря на настойчивые утверждения DeepMind о том, что модель с меньшей вероятностью будет галлюцинировать такие элементы, как дополнительные пальцы или «неожиданные объекты», Veo 2 не может полностью очистить зловещую долину.
Обратите внимание на безжизненные глаза этого мультяшного собачьего существа:

И странно скользкая дорога на этом кадре — плюс пешеходы на заднем плане, сливающиеся друг с другом, и здания с физически невозможными фасадами:

Коллинз признал, что есть над чем работать.
«Последовательность и последовательность — это области для роста», — сказал он. «Veo может последовательно следовать подсказкам в течение нескольких минут, но (не может) придерживаться сложных подсказок в долгосрочной перспективе. Точно так же последовательность персонажей может стать проблемой. Также есть куда совершенствоваться в создании сложных деталей, быстрых и сложных движений и продолжении расширения границ реализма».
DeepMind продолжает работать с художниками и продюсерами над совершенствованием своих моделей и инструментов для создания видео, добавил Коллинз.
«Мы начали работать с такими креативщиками, как Дональд Гловер, The Weeknd, d4vd и другими, с самого начала разработки Veo, чтобы по-настоящему понять их творческий процесс и то, как технологии могут помочь воплотить их видение в жизнь», — сказал Коллинз. «Наша работа с создателями Veo 1 послужила основой для разработки Veo 2, и мы с нетерпением ждем возможности сотрудничать с проверенными тестировщиками и создателями, чтобы получить отзывы об этой новой модели».
Безопасность и обучение
Veo 2 обучался на множестве видео. В целом именно так работают модели ИИ: модели, снабжённые примером за примером той или иной формы данных, улавливают закономерности в данных, которые позволяют им генерировать новые данные.
DeepMind не сообщает, где именно они собирали видео для обучения Veo 2, но одним из возможных источников является YouTube; Google владеет YouTube, и компания DeepMind ранее сообщила TechCrunch, что такие модели Google, как Veo, «могут» обучаться на некотором контенте YouTube.
«Veo прошел обучение по использованию высококачественных видеоописаний», — сказал Коллинз. «Пары видео-описание — это видео и связанное с ним описание того, что происходит в этом видео».

В то время как DeepMind через Google размещает инструменты, позволяющие веб-мастерам блокировать роботов лаборатории извлечение обучающих данных с их веб-сайтов, DeepMind не предлагает механизма, позволяющего создателям удалять работы из существующих обучающих наборов. Лаборатория и ее материнская компания утверждают, что модели обучения с использованием общедоступных данных являются добросовестным использованием. Это означает, что DeepMind считает, что не обязана спрашивать разрешение у владельцев данных.
Не все креативщики с этим согласны, особенно в свете исследований, согласно которым в ближайшие годы искусственный интеллект может разрушить десятки тысяч рабочих мест в кино и на телевидении. Несколько компаний, занимающихся искусственным интеллектом, в том числе одноименный стартап, создавший популярное приложение для искусственного интеллекта Midjourney, находятся под прицелом судебных исков, обвиняющих их в нарушении прав художников путем обучения контенту без согласия.
«Мы стремимся сотрудничать с создателями и нашими партнерами для достижения общих целей», — сказал Коллинз. «Мы продолжаем работать с творческим сообществом и людьми в более широкой отрасли, собирая информацию и прислушиваясь к отзывам, в том числе от тех, кто использует VideoFX».
Благодаря тому, как сегодняшние генеративные модели ведут себя при обучении, они несут определенные риски, например, срыгивание, когда модель генерирует зеркальную копию обучающих данных. Решение DeepMind — это фильтры на уровне подсказок, в том числе для агрессивного, графического и откровенного контента.
По словам Коллинза, политика Google по возмещению ущерба, которая обеспечивает защиту определенных клиентов от обвинений в нарушении авторских прав, связанных с использованием ее продуктов, не будет применяться к Veo 2 до тех пор, пока она не станет общедоступной.

Чтобы снизить риск дипфейков, DeepMind заявляет, что использует свою запатентованную технологию создания водяных знаков SynthID для встраивания невидимых маркеров в кадры, генерируемые Veo 2. Однако, как и все технологии создания водяных знаков, SynthID не является надежным.
Обновления изображения
В дополнение к Veo 2, Google DeepMind сегодня утром объявила об обновлении Imagen 3, своей коммерческой модели создания изображений.
Новая версия Imagen 3 распространяется для пользователей ImageFX, инструмента Google для создания изображений, начиная с сегодняшнего дня. По данным DeepMind, он может создавать «более яркие и скомпонованные» изображения и фотографии в таких стилях, как фотореализм, импрессионизм и аниме.
«Это обновление (до Imagen 3) также более точно следует подсказкам и отображает более богатые детали и текстуры», — написал DeepMind в сообщении блога, предоставленном TechCrunch.
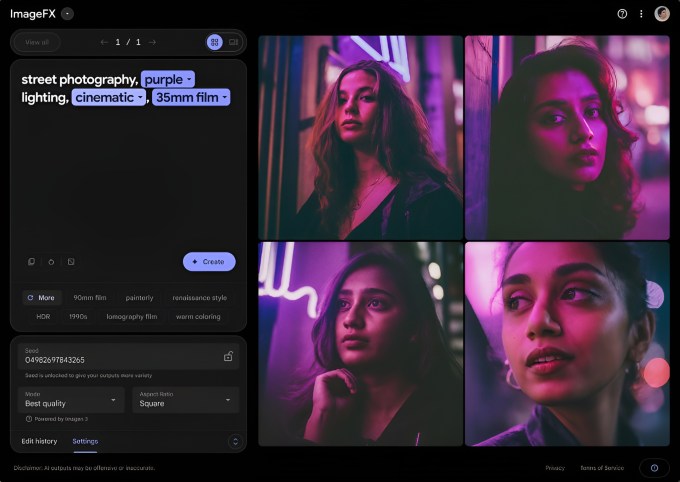
Одновременно с моделью выпускаются обновления пользовательского интерфейса ImageFX. Теперь, когда пользователи вводят подсказки, ключевые термины в этих подсказках станут «чиплетами» с раскрывающимся меню предлагаемых связанных слов. Пользователи могут использовать чипы для повторения написанного или выбирать из ряда автоматически сгенерированных дескрипторов под подсказкой.

