

В прошлом месяце основатели и инвесторы ИИ рассказали TechCrunch, что мы сейчас переживаем «вторую эпоху законов масштабирования», отметив, что устоявшиеся методы улучшения моделей ИИ демонстрируют уменьшающуюся отдачу. Одним из многообещающих новых методов, которые, по их мнению, могут сохранить прибыль, является «масштабирование во время тестирования», которое, по-видимому, и является причиной производительности модели o3 OpenAI, но у него есть свои недостатки.
Большая часть мира ИИ восприняла объявление о модели OpenAI o3 как доказательство того, что прогресс в масштабировании ИИ «не уперся в стену». Модель o3 хорошо справляется с тестами, значительно опережая все другие модели в тесте на общие способности под названием ARC-AGI и набирая 25% в сложном математическом тесте, в котором ни одна другая модель ИИ не набрала более 2%.
Конечно, мы в TechCrunch относимся ко всему этому с недоверием, пока не сможем протестировать o3 самостоятельно (пока очень немногие пробовали это). Но еще до выхода o3 мир искусственного интеллекта уже убежден, что что-то серьезное изменилось.
Соавтор серии моделей OpenAI Ноам Браун отметил в пятницу, что стартап объявляет о впечатляющих достижениях o3 всего через три месяца после того, как стартап объявил об o1 – относительно короткий срок для такого скачка производительности.
«У нас есть все основания полагать, что эта траектория продолжится», — сказал Браун в своем твиттере.
Соучредитель Anthropic Джек Кларк заявил в своем блоге в понедельник, что o3 является свидетельством того, что прогресс ИИ «в 2025 году будет быстрее, чем в 2024 году». (Имейте в виду, что Anthropic — особенно ее способность привлекать капитал — выгодно предположить, что законы о масштабировании ИИ продолжают действовать, даже если Кларк дополняет конкурента.)
В следующем году, по словам Кларка, мир ИИ объединит масштабирование во время тестирования и традиционные методы масштабирования перед обучением, чтобы получить еще большую отдачу от моделей ИИ. Возможно, он предполагает, что Anthropic и другие поставщики моделей ИИ выпустят собственные модели рассуждения в 2025 году, как это сделал Google на прошлой неделе.
Масштабирование времени тестирования означает, что OpenAI использует больше вычислений на этапе вывода ChatGPT, в период времени после того, как вы нажмете Enter в командной строке. Непонятно, что именно происходит за кулисами: OpenAI либо использует больше компьютерных чипов для ответа на вопрос пользователя, запускает более мощные чипы вывода, либо запускает эти чипы в течение более длительных периодов времени — в некоторых случаях от 10 до 15 минут — прежде чем ИИ выдает ответ. Мы не знаем всех подробностей того, как создавался o3, но эти тесты являются первым признаком того, что масштабирование во время тестирования может повысить производительность моделей ИИ.
Хотя o3 может дать некоторым новую веру в прогресс законов масштабирования ИИ, новейшая модель OpenAI также использует ранее невиданный уровень вычислений, что означает более высокую цену за ответ.
«Возможно, единственное важное предостережение здесь — это понимание того, что одна из причин, почему O3 настолько лучше, заключается в том, что его запуск во время вывода требует больше денег — возможность использовать вычисления во время тестирования означает, что в некоторых проблемах вы можете превратить вычисления в лучший ответ. », — пишет Кларк в своем блоге. «Это интересно, потому что это сделало затраты на эксплуатацию систем искусственного интеллекта несколько менее предсказуемыми — раньше вы могли подсчитать, сколько стоит обслуживание генеративной модели, просто взглянув на модель и стоимость получения заданного результата».
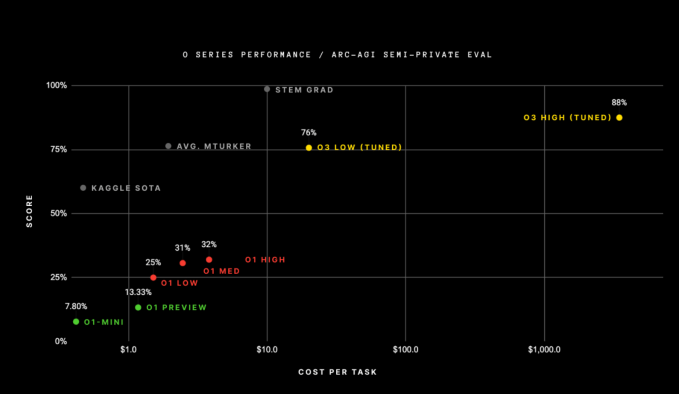
Кларк и другие указали на результаты o3 по тесту ARC-AGI — сложному тесту, используемому для оценки прорывов в AGI — как на индикатор его прогресса. Стоит отметить, что прохождение этого теста, по мнению его создателей, не означает модель ИИ. добился AGI, а скорее один из способов измерения прогресса в достижении туманной цели. Тем не менее, модель o3 превзошла все предыдущие модели ИИ, прошедшие тест, набрав 88% в одной из попыток. Следующая лучшая модель искусственного интеллекта OpenAI, o1, набрала всего 32%.
Но логарифмическая ось X на этой диаграмме может кого-то встревожить. Версия o3 с высокими оценками использовала вычислительные ресурсы на сумму более 1000 долларов США для каждой задачи. Модели o1 использовали около 5 долларов вычислительных ресурсов на задачу, а o1-mini — всего несколько центов.
Создатель теста ARC-AGI Франсуа Шолле пишет в блоге, что OpenAI использовал примерно в 170 раз больше вычислений для получения результата в 88% по сравнению с высокоэффективной версией o3, которая набрала всего на 12% меньше. Версия o3 с высокими показателями использовала более 10 000 долларов ресурсов для завершения теста, что делает слишком дорогим участие в борьбе за приз ARC — непобедимое соревнование для моделей ИИ, преодолевших тест ARC.
Тем не менее, Шолле говорит, что o3 все равно стал прорывом для моделей искусственного интеллекта.
«o3 — это система, способная адаптироваться к задачам, с которыми она никогда раньше не сталкивалась, возможно, приближаясь к производительности человеческого уровня в области ARC-AGI», — сказал Шолле в блоге. «Конечно, такая универсальность обходится дорого и пока не совсем экономична: вы можете заплатить человеку за решение задач ARC-AGI примерно по 5 долларов за задачу (мы знаем, мы это делали), потребляя при этом всего лишь несколько центов. в энергетике».
Пока преждевременно говорить о точных ценах на все это — мы видели, как цены на модели искусственного интеллекта резко упали в прошлом году, а OpenAI еще не объявила, сколько на самом деле будет стоить o3. Однако эти цены показывают, сколько вычислительных ресурсов потребуется, чтобы хотя бы незначительно преодолеть барьеры производительности, установленные сегодня ведущими моделями ИИ.
Это вызывает некоторые вопросы. Для чего вообще нужен o3? И сколько еще вычислений необходимо, чтобы добиться большего успеха в умозаключениях с помощью o4, o5 или чего-либо еще, что OpenAI называет своими следующими моделями рассуждений?
Не похоже, что o3 или его преемники станут для кого-то «ежедневным драйвером», каким могут быть GPT-4o или Google Search. Эти модели просто используют слишком много вычислений, чтобы отвечать на небольшие вопросы в течение дня, например: «Как «Кливленд Браунс» все же смогут выйти в плей-офф 2024 года?»
Вместо этого кажется, что модели искусственного интеллекта с масштабированными вычислениями во время тестирования могут быть хороши только для подсказок общей картины, таких как: «Как Кливленд Браунс могут стать франшизой Суперкубка в 2027 году?» Даже в этом случае, возможно, высокие затраты на вычисления окупаются только в том случае, если вы генеральный менеджер «Кливленд Браунс» и используете эти инструменты для принятия важных решений.
Учреждения с глубокими карманами, возможно, единственные, кто может позволить себе o3, по крайней мере, для начала, как отмечает в своем твиттере профессор Уортона Итан Моллик.
Мы уже видели, как OpenAI выпустила уровень за 200 долларов для использования высокопроизводительной версии o1, но, как сообщается, стартап взвесил возможность создания планов подписки стоимостью до 2000 долларов. Когда вы увидите, сколько вычислительных ресурсов использует o3, вы поймете, почему OpenAI это учитывает.
Но у использования o3 для высокоэффективной работы есть свои недостатки. Как отмечает Шолле, o3 — это не AGI, и он по-прежнему не справляется с некоторыми очень простыми задачами, с которыми человек справился бы довольно легко.
Это неудивительно, поскольку в больших языковых моделях все еще существует огромная проблема галлюцинаций, которую o3 и вычисления во время тестирования, похоже, не решили. Вот почему ChatGPT и Gemini включают заявления об отказе от ответственности под каждым ответом, предлагая пользователям не доверять ответам за чистую монету. Предположительно, AGI, если бы она когда-либо была достигнута, не нуждалась бы в таком отказе от ответственности.
Одним из способов получить больше преимуществ от масштабирования во время тестирования может стать улучшение микросхем вывода ИИ. Нет недостатка в стартапах, занимающихся именно этой задачей, таких как Groq или Cerebras, в то время как другие стартапы разрабатывают более экономичные чипы искусственного интеллекта, такие как MatX. Генеральный партнер Andreessen Horowitz Анжни Мидха ранее сообщил TechCrunch, что ожидает, что эти стартапы будут играть более важную роль в дальнейшем масштабировании времени тестирования.
Хотя o3 является заметным улучшением производительности моделей искусственного интеллекта, он поднимает несколько новых вопросов, касающихся использования и затрат. Тем не менее, производительность o3 подтверждает утверждение о том, что вычисления во время тестирования — это следующий лучший способ масштабирования моделей ИИ в технологической отрасли.

