Известный тест на общий искусственный интеллект (AGI) близок к решению. Но создатели тестов говорят, что это указывает на недостатки в конструкции теста, а не на настоящий исследовательский прорыв.
В 2019 году Франсуа Шолле, ведущая фигура в мире искусственного интеллекта, представил тест ARC-AGI, сокращение от «Абстрактный корпус рассуждений для общего искусственного интеллекта». Разработанный для оценки того, может ли система ИИ эффективно приобретать новые навыки за пределами данных, на которых она была обучена, ARC-AGI, утверждает Франсуа, остается единственным тестом ИИ для измерения прогресса в достижении общего интеллекта (хотя были предложены и другие).
До этого года самый эффективный ИИ мог решить лишь чуть менее трети задач ARC-AGI. Шолле обвинил индустрию в том, что она сосредоточила внимание на моделях большого языка (LLM), которые, по его мнению, не способны к реальному «рассуждению».
«У студентов-магистрантов проблемы с обобщениями, поскольку они полностью полагаются на запоминание», — сказал он в серии постов на X в феврале. «Они ломаются из-за всего, чего не было в их тренировочных данных».
По мнению Шолле, LLM — это статистические машины. Обучившись на множестве примеров, они изучают закономерности в этих примерах, чтобы делать прогнозы, например, фраза «кому» в электронном письме обычно предшествует фразе «это может касаться».
Шолле утверждает, что, хотя студенты магистратуры могут быть способны запоминать «образцы рассуждений», маловероятно, что они смогут генерировать «новые рассуждения» на основе новых ситуаций. «Если вам нужно пройти обучение на многих примерах шаблона, даже если он неявный, чтобы изучить его повторно используемое представление, вы должны запоминать», — утверждает Шолле в другом посте.
Чтобы стимулировать исследования, выходящие за рамки магистратуры, в июне Чолле и соучредитель Zapier Майк Кнуп объявили конкурс на 1 миллион долларов на создание искусственного интеллекта с открытым исходным кодом, способного превзойти ARC-AGI. Из 17 789 заявок лучшие набрали 55,5%, что примерно на 20% выше, чем у лучшего бомбардира 2023 года, хотя и меньше 85% порога «человеческого уровня», необходимого для победы.
Однако это не значит, что мы примерно на 20% ближе к AGI, говорит Кнооп.
Сегодня мы объявляем победителей ARC Prize 2024. Мы также публикуем обширный технический отчет о том, что мы узнали из конкурса (ссылка в следующем твите).
Современный уровень вырос с 33% до 55,5%, что стало самым большим годовым ростом, который мы видели с 2020 года.…
— Франсуа Шолле (@fchollet) 6 декабря 2024 г.
В своем блоге Кнооп сказал, что многие из представленных в ARC-AGI задач смогли «грубым путем» найти решение, предполагая, что «большая часть» задач ARC-AGI «(не) несет в себе особой важности». полезный сигнал для общей разведки».
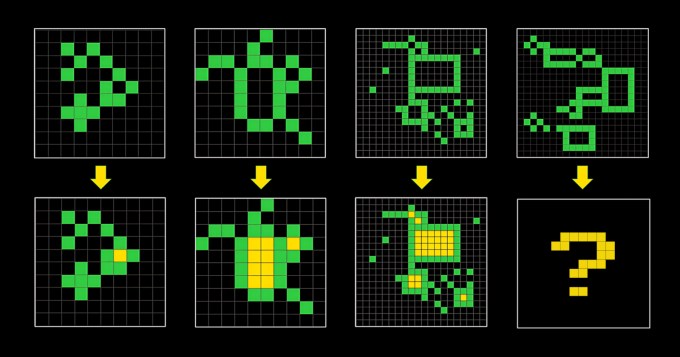
ARC-AGI состоит из задач, похожих на головоломки, в которых ИИ должен, имея сетку разноцветных квадратов, сгенерировать правильную сетку «ответов». Проблемы были созданы для того, чтобы заставить ИИ адаптироваться к новым проблемам, с которыми он раньше не сталкивался. Но неясно, достигают ли они этого.
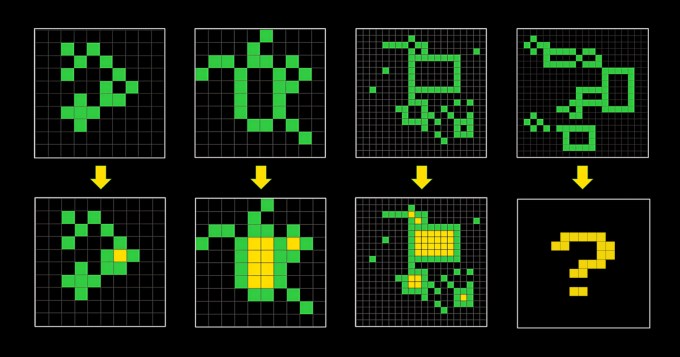
«(ARC-AGI) не изменилась с 2019 года и не идеальна», — признал Кнооп в своем посте.
Франсуа и Кноп также столкнулись с критикой за переоценку ARC-AGI как эталона AGI — в то время, когда само определение AGI вызывает горячие споры. Один из сотрудников OpenAI недавно заявил, что AGI «уже» достигнут, если определить AGI как ИИ, «лучше, чем большинство людей в большинстве задач».
Кнуп и Шолле говорят, что планируют выпустить тест ARC-AGI второго поколения для решения этих проблем одновременно с конкурсом 2025 года. «Мы продолжим направлять усилия исследовательского сообщества на то, что мы считаем наиболее важными нерешенными проблемами в области ИИ, и ускоряем сроки создания AGI», — написал Шолле в X-посте.
Исправления, вероятно, не дадутся легко. Если недостатки первого теста ARC-AGI являются каким-либо показателем, то определение интеллекта для ИИ будет столь же трудным и воспалительным, как и для людей.